「力扣」第 126 题:单词接龙 II
- 链接:126. 单词接龙 II;
给定两个单词(beginWord 和 endWord)和一个字典 *wordList,找出所有从 *beginWord 到 endWord 的最短转换序列。转换需遵循如下规则:
- 每次转换只能改变一个字母。
- 转换过程中的中间单词必须是字典中的单词。
说明:
- 如果不存在这样的转换序列,返回一个空列表。
- 所有单词具有相同的长度。
- 所有单词只由小写字母组成。
- 字典中不存在重复的单词。
- 你可以假设 beginWord 和 endWord 是非空的,且二者不相同。
示例 1:
输入: beginWord = "hit", endWord = "cog", wordList = ["hot","dot","dog","lot","log","cog"] 输出: [ ["hit","hot","dot","dog","cog"], ["hit","hot","lot","log","cog"] ]示例 2:
输入: beginWord = "hit" endWord = "cog" wordList = ["hot","dot","dog","lot","log"] 输出: [] 解释: endWord "cog" 不在字典中,所以不存在符合要求的转换序列。
解题思路:
这道题是一道常见的考题,没有特别难理解的技巧,完全可以由已有的知识迁移过来。主要考察的是编码和耐心调试的能力。以下代码量较多,仅供参考,建议读者理解清楚解题思想以后,自行编码、调试完成。
思路分析:
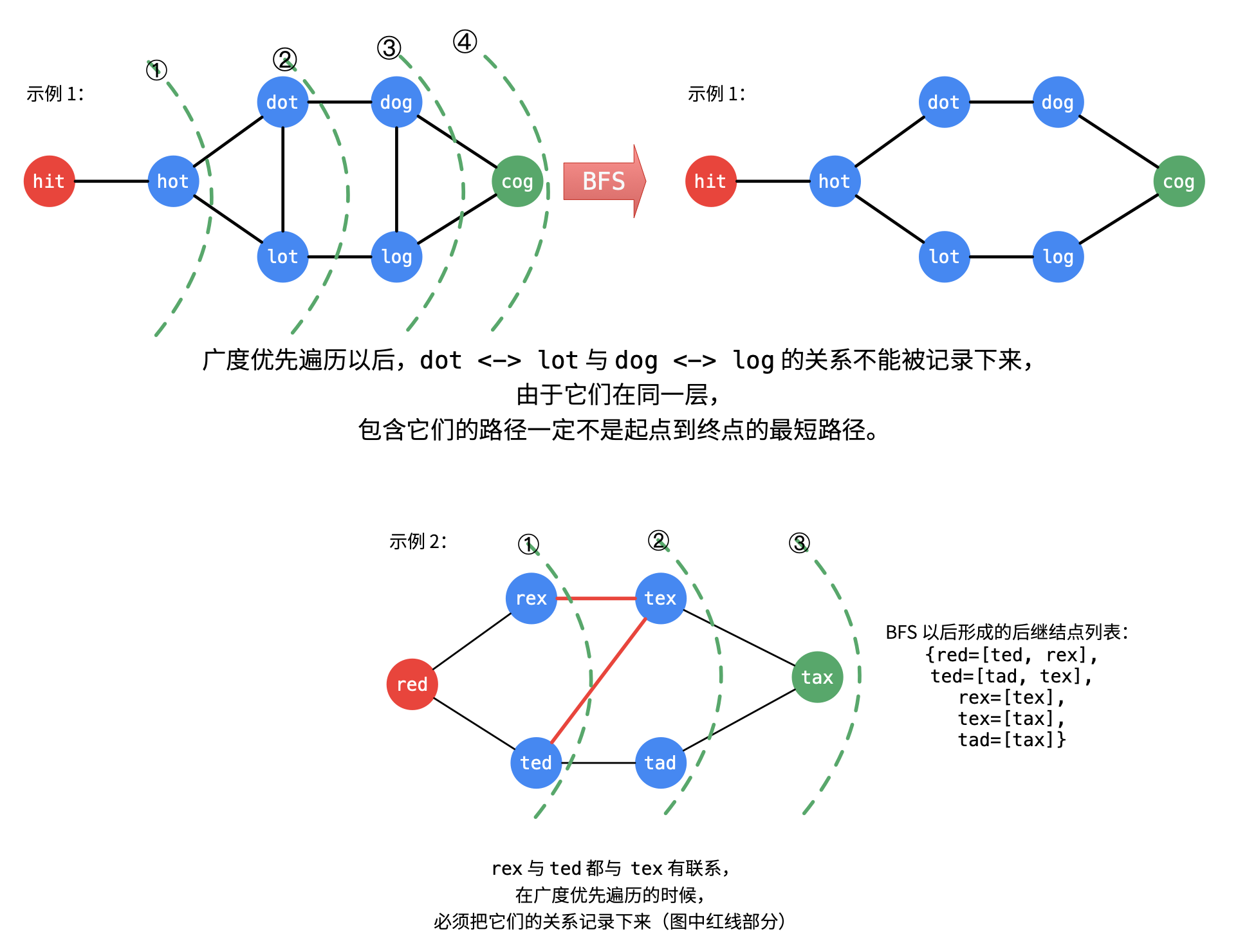
- 单词列表、起点、终点构成无向图,容易想到使用广度优先遍历找到最短路径:图中广度优先遍历要使用到;
- 队列;
- 标记是否访问过的「布尔数组」或者「哈希表」
visited,这里 key 是字符串,故使用哈希表;
说明:本题可以在 wordList (添加到哈希表以后)上做减法,不过标准的、更可靠的做法是,另外使用一个 visited 哈希表,将访问以后的单词添加到 visited 哈希表中,下面给出的参考代码都采用这种不节约空间的做法。
- 重点:由于要记录所有的路径,广度优先遍历「当前层」到「下一层」的所有路径都得记录下来。因此找到下一层的结点
wordA以后,不能马上添加到visited哈希表里,还需要检查当前队列中未出队的单词是否还能与wordA建立联系; - 广度优先遍历位于同一层的单词,即使有联系,也是不可以被记录下来的,这是因为同一层的连接肯定不是起点到终点的最短路径的边;
- 使用 BFS 的同时记录遍历的路径,形式:哈希表。哈希表的 key 记录了「顶点字符串」,哈希表的值 value 记录了 key 对应的字符串在广度优先遍历的过程中得到的所有后继结点列表
successors; - 最后根据
successors,使用回溯算法(全程使用一份路径变量搜索所有可能结果的深度优先遍历算法)得到所有的最短路径。
方法一:广度优先遍历
如果开始就构建图,结果可能会超时,这里采用的方法是:先把
wordList存入哈希表,然后是一边遍历,一边找邻居,进而构建图,这是解决这个问题的特点;每一层使用一个新的
nextLevelVisited哈希表,记录当前层的下一层可以访问到哪些结点。直到上一层队列里的值都出队以后,nextLevelVisited哈希表才添加到总的visited哈希表,这样记录当前结点和广度优先遍历到的子结点列表才不会遗漏。
为此,设计算法流程如下:
- 第 1 步:使用广度优先遍历找到终点单词,并且记录下沿途经过的所有结点,以邻接表形式存储;
- 第 2 步:通过邻接表,使用回溯算法得到所有从起点单词到终点单词的路径。
参考代码 1:
Java 代码:
import java.util.ArrayDeque;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Deque;
import java.util.HashMap;
import java.util.HashSet;
import java.util.LinkedList;
import java.util.List;
import java.util.Map;
import java.util.Queue;
import java.util.Set;
public class Solution {
public List<List<String>> findLadders(String beginWord, String endWord, List<String> wordList) {
// 先将 wordList 放到哈希表里,便于判断某个单词是否在 wordList 里
Set<String> wordSet = new HashSet<>(wordList);
List<List<String>> res = new ArrayList<>();
if (wordSet.size() == 0 || !wordSet.contains(endWord)) {
return res;
}
// 第 1 步:使用广度优先遍历得到后继结点列表 successors
// key:字符串,value:广度优先遍历过程中 key 的后继结点列表
Map<String, Set<String>> successors = new HashMap<>();
boolean found = bfs(beginWord, endWord, wordSet, successors);
if (!found) {
return res;
}
// 第 2 步:基于后继结点列表 successors ,使用回溯算法得到所有最短路径列表
Deque<String> path = new ArrayDeque<>();
path.addLast(beginWord);
dfs(beginWord, endWord, successors, path, res);
return res;
}
private boolean bfs(String beginWord, String endWord, Set<String> wordSet,
Map<String, Set<String>> successors) {
Queue<String> queue = new LinkedList<>();
queue.offer(beginWord);
// 记录访问过的单词
Set<String> visited = new HashSet<>();
visited.add(beginWord);
boolean found = false;
int wordLen = beginWord.length();
// 当前层访问过的结点,当前层全部遍历完成以后,再添加到总的 visited 集合里
Set<String> nextLevelVisited = new HashSet<>();
while (!queue.isEmpty()) {
int currentSize = queue.size();
for (int i = 0; i < currentSize; i++) {
String currentWord = queue.poll();
char[] charArray = currentWord.toCharArray();
for (int j = 0; j < wordLen; j++) {
char originChar = charArray[j];
for (char k = 'a'; k <= 'z'; k++) {
if (charArray[j] == k) {
continue;
}
charArray[j] = k;
String nextWord = new String(charArray);
if (wordSet.contains(nextWord)) {
if (!visited.contains(nextWord)) {
if (nextWord.equals(endWord)) {
found = true;
}
nextLevelVisited.add(nextWord);
queue.offer(nextWord);
// 维护 successors 的定义
successors.computeIfAbsent(currentWord, a -> new HashSet<>());
successors.get(currentWord).add(nextWord);
}
}
}
charArray[j] = originChar;
}
}
if (found) {
break;
}
visited.addAll(nextLevelVisited);
nextLevelVisited.clear();
}
return found;
}
private void dfs(String beginWord, String endWord,
Map<String, Set<String>> successors,
Deque<String> path, List<List<String>> res) {
if (beginWord.equals(endWord)) {
res.add(new ArrayList<>(path));
return;
}
if (!successors.containsKey(beginWord)) {
return;
}
Set<String> successorWords = successors.get(beginWord);
for (String nextWord : successorWords) {
path.addLast(nextWord);
dfs(nextWord, endWord, successors, path, res);
path.removeLast();
}
}
public static void main(String[] args) {
String[] words = {"rex", "ted", "tex", "tad", "tax"};
List<String> wordList = new ArrayList<>();
Collections.addAll(wordList, words);
Solution solution = new Solution();
String beginWord = "red";
String endWord = "tax";
List<List<String>> res = solution.findLadders(beginWord, endWord, wordList);
System.out.println(res);
}
}Python 代码:
from collections import defaultdict
from typing import List
from collections import deque
import string
class Solution:
def findLadders(self, beginWord: str, endWord: str, wordList: List[str]) -> List[List[str]]:
# 先将 wordList 放到哈希表里,便于判断某个单词是否在 wordList 里
word_set = set(wordList)
res = []
if len(word_set) == 0 or endWord not in word_set:
return res
successors = defaultdict(set)
# 第 1 步:使用广度优先遍历得到后继结点列表 successors
# key:字符串,value:广度优先遍历过程中 key 的后继结点列表
found = self.__bfs(beginWord, endWord, word_set, successors)
if not found:
return res
# 第 2 步:基于后继结点列表 successors ,使用回溯算法得到所有最短路径列表
path = [beginWord]
self.__dfs(beginWord, endWord, successors, path, res)
return res
def __bfs(self, beginWord, endWord, word_set, successors):
queue = deque()
queue.append(beginWord)
visited = set()
visited.add(beginWord)
found = False
word_len = len(beginWord)
next_level_visited = set()
while queue:
current_size = len(queue)
for i in range(current_size):
current_word = queue.popleft()
word_list = list(current_word)
for j in range(word_len):
origin_char = word_list[j]
for k in string.ascii_lowercase:
word_list[j] = k
next_word = ''.join(word_list)
if next_word in word_set:
if next_word not in visited:
if next_word == endWord:
found = True
next_level_visited.add(next_word)
queue.append(next_word)
successors[current_word].add(next_word)
word_list[j] = origin_char
if found:
break
# 取两集合全部的元素(并集,等价于将 next_level_visited 里的所有元素添加到 visited 里)
visited |= next_level_visited
next_level_visited.clear()
return found
def __dfs(self, beginWord, endWord, successors, path, res):
if beginWord == endWord:
res.append(path[:])
return
if beginWord not in successors:
return
successor_words = successors[beginWord]
for next_word in successor_words:
path.append(next_word)
self.__dfs(next_word, endWord, successors, path, res)
path.pop()
if __name__ == '__main__':
beginWord = "hit"
endWord = "cog"
wordList = ["hot", "dot", "dog", "lot", "log", "cog"]
solution = Solution()
res = solution.findLadders(beginWord, endWord, wordList)
print(res)复杂度分析:(如有错误还请朋友们请指正)
- 时间复杂度:$O(N \times 26 \times wordLen + N 2^N)$
- 广度优先遍历:最差情况下每个结点遍历一次,时间复杂度为 $O(N)$,这里 $N$ 是单词列表的单词总数;
- 建图:一开始将所有单词放进哈希表 $O(N)$,每一个单词查找邻居 $O(26 \times wordLen)$,
wordLen表示单词的长度,一般而言不会很大,比起 $N$ 会小很多,甚至可以视为常数; - 回溯算法:指数级别 $O(2^N)$,记录每一个结果 $O(N)$,这里认为最坏情况下,最短路径为单词列表的单词总数。
- 空间复杂度:$O(ways \times N \times wordLen)$,这里 ways 表示最短路径的方案数。
说明:
successors.computeIfAbsent(currentWord, a -> new HashSet<>());
successors.get(currentWord).add(nextWord);以上代码从 Java 1.8 以后支持,等价的代码片段是:
// 维护 successors 的定义
if (successors.containsKey(currentWord)) {
successors.get(currentWord).add(nextWord);
} else {
Set<String> newSet = new HashSet<>();
newSet.add(nextWord);
successors.put(currentWord, newSet);
}方法二:双向广度优先遍历
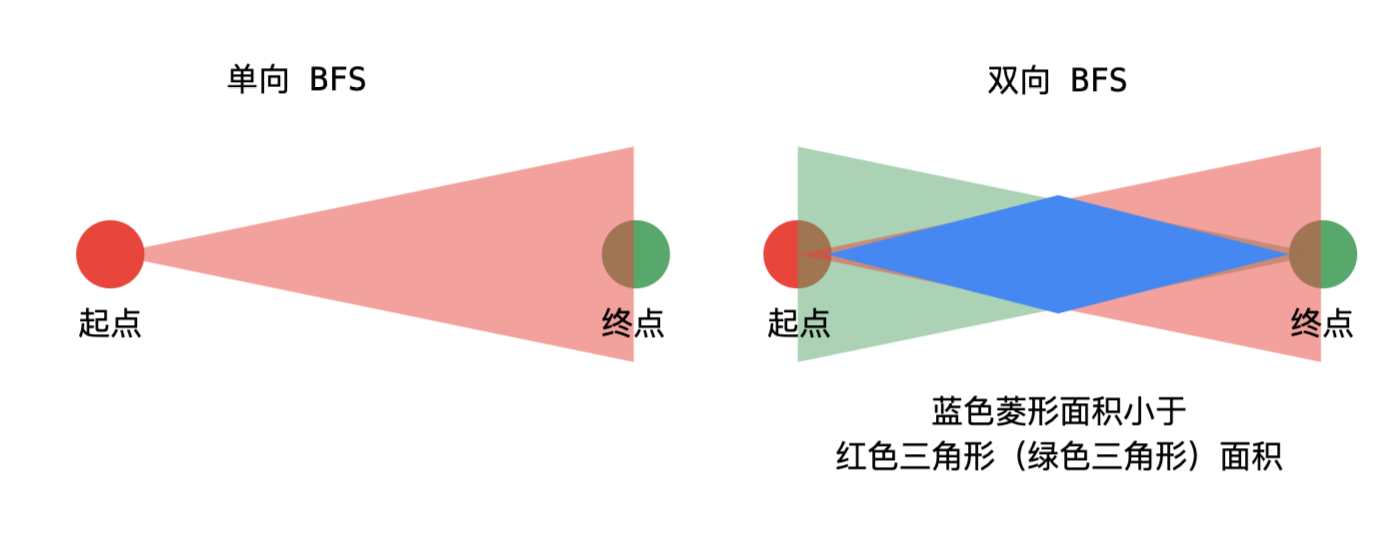
- 由于我们这个问题知道目标值,因此可以让起点和终点「同时」做 BFS,直到它们又交集,两边一起扩散形成的路径也是最短路径;
- 双向 BFS 有点像山洞挖隧道,两边一起挖,直到打通为止。双向 BFS 搜索到的集合更小,相当于做了一些剪枝操作,因此会更快一些。
编码说明:
- 参考代码 2 与参考代码 1 仅仅把「广度优先遍历」方法的实现改成了「双向广度优先遍历」,回溯的代码是一样的;
beginVisited和endVisited交替使用,实现类似队列(符合顺序性,先进先出)的效果;- 注意:不一定非要严格按照「一左一右」的顺序交替向中间扩散,每次都从较小的集合扩散,统计意义上搜索的范围更小;
- 理解下面设计
forward变量的作用,虽然是双向扩散,但是记录「后继结点列表」的时候方向固定。
参考代码 2:
Java 代码:
import java.util.ArrayDeque;
import java.util.ArrayList;
import java.util.Deque;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
import java.util.Set;
public class Solution {
public List<List<String>> findLadders(String beginWord, String endWord, List<String> wordList) {
// 先将 wordList 放到哈希表里,便于判断某个单词是否在 wordList 里
List<List<String>> res = new ArrayList<>();
Set<String> wordSet = new HashSet<>(wordList);
if (wordSet.size() == 0 || !wordSet.contains(endWord)) {
return res;
}
// 第 1 步:使用双向广度优先遍历得到后继结点列表 successors
// key:字符串,value:广度优先遍历过程中 key 的后继结点列表
Map<String, Set<String>> successors = new HashMap<>();
boolean found = bidirectionalBfs(beginWord, endWord, wordSet, successors);
if (!found) {
return res;
}
// 第 2 步:基于后继结点列表 successors ,使用回溯算法得到所有最短路径列表
Deque<String> path = new ArrayDeque<>();
path.addLast(beginWord);
dfs(beginWord, endWord, successors, path, res);
return res;
}
private boolean bidirectionalBfs(String beginWord,
String endWord,
Set<String> wordSet,
Map<String, Set<String>> successors) {
// 记录访问过的单词
Set<String> visited = new HashSet<>();
visited.add(beginWord);
visited.add(endWord);
Set<String> beginVisited = new HashSet<>();
beginVisited.add(beginWord);
Set<String> endVisited = new HashSet<>();
endVisited.add(endWord);
int wordLen = beginWord.length();
boolean forward = true;
boolean found = false;
// 在保证了 beginVisited 总是较小(可以等于)大小的集合前提下,&& !endVisited.isEmpty() 可以省略
while (!beginVisited.isEmpty() && !endVisited.isEmpty()) {
// 一直保证 beginVisited 是相对较小的集合,方便后续编码
if (beginVisited.size() > endVisited.size()) {
Set<String> temp = beginVisited;
beginVisited = endVisited;
endVisited = temp;
// 只要交换,就更改方向,以便维护 successors 的定义
forward = !forward;
}
Set<String> nextLevelVisited = new HashSet<>();
// 默认 beginVisited 是小集合,因此从 beginVisited 出发
for (String currentWord : beginVisited) {
char[] charArray = currentWord.toCharArray();
for (int i = 0; i < wordLen; i++) {
char originChar = charArray[i];
for (char j = 'a'; j <= 'z'; j++) {
if (charArray[i] == j) {
continue;
}
charArray[i] = j;
String nextWord = new String(charArray);
if (wordSet.contains(nextWord)) {
if (endVisited.contains(nextWord)) {
found = true;
// 在另一侧找到单词以后,还需把这一层关系添加到「后继结点列表」
addToSuccessors(successors, forward, currentWord, nextWord);
}
if (!visited.contains(nextWord)) {
nextLevelVisited.add(nextWord);
addToSuccessors(successors, forward, currentWord, nextWord);
}
}
}
charArray[i] = originChar;
}
}
beginVisited = nextLevelVisited;
visited.addAll(nextLevelVisited);
if (found) {
break;
}
}
return found;
}
private void dfs(String beginWord,
String endWord,
Map<String, Set<String>> successors,
Deque<String> path,
List<List<String>> res) {
if (beginWord.equals(endWord)) {
res.add(new ArrayList<>(path));
return;
}
if (!successors.containsKey(beginWord)) {
return;
}
Set<String> successorWords = successors.get(beginWord);
for (String successor : successorWords) {
path.addLast(successor);
dfs(successor, endWord, successors, path, res);
path.removeLast();
}
}
private void addToSuccessors(Map<String, Set<String>> successors, boolean forward,
String currentWord, String nextWord) {
if (!forward) {
String temp = currentWord;
currentWord = nextWord;
nextWord = temp;
}
// Java 1.8 以后支持
successors.computeIfAbsent(currentWord, a -> new HashSet<>());
successors.get(currentWord).add(nextWord);
}
public static void main(String[] args) {
List<String> wordList = new ArrayList<>();
wordList.add("hot");
wordList.add("dot");
wordList.add("dog");
wordList.add("lot");
wordList.add("log");
wordList.add("cog");
Solution solution = new Solution();
String beginWord = "hit";
String endWord = "cog";
List<List<String>> res = solution.findLadders(beginWord, endWord, wordList);
System.out.println(res);
}
}Python 代码:
from collections import defaultdict
from typing import List
from collections import deque
import string
class Solution:
def findLadders(self, beginWord: str, endWord: str, wordList: List[str]) -> List[List[str]]:
# 先将 wordList 放到哈希表里,便于判断某个单词是否在 wordList 里
word_set = set(wordList)
res = []
if len(word_set) == 0 or endWord not in word_set:
return res
successors = defaultdict(set)
# 第 1 步:使用广度优先遍历得到后继结点列表 successors
# key:字符串,value:广度优先遍历过程中 key 的后继结点列表
found = self.__bidirectional_bfs(beginWord, endWord, word_set, successors)
if not found:
return res
# 第 2 步:基于后继结点列表 successors ,使用回溯算法得到所有最短路径列表
path = [beginWord]
self.__dfs(beginWord, endWord, successors, path, res)
return res
def __bidirectional_bfs(self, beginWord, endWord, word_set, successors):
visited = set()
visited.add(beginWord)
visited.add(endWord)
begin_visited = set()
begin_visited.add(beginWord)
end_visited = set()
end_visited.add(endWord)
found = False
forward = True
word_len = len(beginWord)
while begin_visited:
if len(begin_visited) > len(end_visited):
begin_visited, end_visited = end_visited, begin_visited
forward = not forward
next_level_visited = set()
for current_word in begin_visited:
word_list = list(current_word)
for j in range(word_len):
origin_char = word_list[j]
for k in string.ascii_lowercase:
word_list[j] = k
next_word = ''.join(word_list)
if next_word in word_set:
if next_word in end_visited:
found = True
# 在另一侧找到单词以后,还需把这一层关系添加到「后继结点列表」
self.__add_to_successors(successors, forward, current_word, next_word)
if next_word not in visited:
next_level_visited.add(next_word)
self.__add_to_successors(successors, forward, current_word, next_word)
word_list[j] = origin_char
begin_visited = next_level_visited
# 取两集合全部的元素(并集,等价于将 next_level_visited 里的所有元素添加到 visited 里)
visited |= next_level_visited
if found:
break
return found
def __add_to_successors(self, successors, forward, current_word, next_word):
if forward:
successors[current_word].add(next_word)
else:
successors[next_word].add(current_word)
def __dfs(self, beginWord, endWord, successors, path, res):
if beginWord == endWord:
res.append(path[:])
return
if beginWord not in successors:
return
successor_words = successors[beginWord]
for next_word in successor_words:
path.append(next_word)
self.__dfs(next_word, endWord, successors, path, res)
path.pop()
if __name__ == '__main__':
beginWord = "hit"
endWord = "cog"
wordList = ["hot", "dot", "dog", "lot", "log", "cog"]
solution = Solution()
res = solution.findLadders(beginWord, endWord, wordList)
print(res)


